Table of Contents
Share this article
Once in a while, the AI community—and even the stock market—is shaken by breakthroughs that redefine the landscape. This time, it was DeepSeek that marked a major inflection point in AI, particularly in natural language processing. The competition to develop cost-effective and reliable large language models has intensified, especially with OpenAI’s release of its reasoning models, O1 and O3. However, DeepSeek’s impact goes beyond just a high-performing model. As an open-source alternative, it offers a cheaper yet highly capable solution. More than just DeepSeek-R1, they introduced a novel reinforcement learning framework and an effective distillation technique, enabling smaller, more efficient models. Given its success, we expect other big-tech companies to follow suit, adopting similar strategies to optimize cost and performance. To assess DeepSeek’s capabilities beyond its well-documented strengths in math, we tested its models on various NLP tasks, exploring how well they generalize across different domains.
What is DeepSeek-R1?
DeepSeek-R1 is an open-source reasoning model recently published as the reasoning partner of DeepSeek-v3, developed by DeepSeek-AI. It was created using a novel reinforcement learning technique, originally used for DeepSeekMath, called Group Relative Policy Optimization (GRPO). This technique is more resource-effective than other state-of-art techniques such as Proximal Policy Optimization (PPO).
As a result, DeepSeek-R1 has quickly emerged as a strong competitor to OpenAI’s o1 and o3 reasoning models—not only due to its lower cost but also because both the model and its distilled versions are open-source. Furthermore, its training procedure is publicly documented and has been successfully reproduced by multiple teams. See, for example, this model and this post.
Moreover, DeepSeek-R1 is more than just a model—it didn’t shock the AI community and impact NVIDIA stock solely because of its relatively low training cost. The DeepSeek team also released smaller open-source reasoning models, distilled from DeepSeek-R1, that can run on budget machines. This, along with its reproducible reinforcement learning technique, has provided powerful open-source tools and new training paradigms, further contributing to the democratization of AI.
How Was DeepSeek-R1 Trained?
After reviewing DeepSeek-R1’s paper, we can identify two key ingredients that were crucial in its training process: reinforcement learning and a specific form of output that the model was required to produce, which was also shaped through reinforcement learning. The image below illustrates the output format where an “aha moment” appeared when asking the model why is the sky blue? DeepSeek-R1 generates a chain of thinking with human-like self-verification and reflection. In this example, it questions why we see only blue if all colors are scattered in the atmosphere.

The model learned to generate a chain of thought within the <think> ... </think> environment before providing either an answer or a summary, depending on the question. During reinforcement learning, it was rewarded for following several rule-based guidelines, particularly those focused on mathematical and logical problems.
In fact, these two ingredients alone were enough to produce an earlier model, DeepSeek-R1-Zero, which already demonstrated remarkable reasoning capabilities. However, it still had some limitations, which we will discuss below. Before proceeding, let’s first examine what is reinforcement learning and the particular technique behind these models.
Reinforcement Learning
Reinforcement learning (RL) is a type of machine learning where an agent learns to make decisions by interacting with its environment and receiving feedback in the form of rewards or penalties. The goal of RL is to find a strategy, known as a policy, that maximizes cumulative rewards over time. Unlike traditional supervised learning, where models learn from labeled data, RL is centered around exploring actions and learning from the consequences, making it ideal for tasks with sequential decisions or where the optimal solution is not immediately clear.
RL has become a key component in training large language models (LLMs), helping them refine their outputs based on feedback and optimization strategies. Different RL paradigms have been employed to improve language models, each with its own advantages. Traditional methods include Reinforcement Learning from Human Feedback (RLHF), where human preferences guide the model’s learning process, and Actor-Critic methods, which optimize decision-making by balancing exploration (trying new responses) and exploitation (choosing the best-known responses).
A widely used method in modern LLMs is Proximal Policy Optimization (PPO), which stabilizes training by preventing large, unstable updates to the model’s decision-making policy. PPO has been a standard choice for fine-tuning AI models, including those developed by OpenAI and other research groups.
GRPO
However, newer approaches aim to improve efficiency and reduce computational costs. One such innovation is Group Relative Policy Optimization (GRPO). Some key features of this technique include:
- Evaluation and reward calculation within a set of outcomes that the old policy (in this case, the LLM) produces given some question or query. This is why the model is called relative and does not require a value model.
- To prevent large, disruptive changes, the technique employs clipping, which restricts adjustments, and uses a reference model to ensure that the new model does not deviate too far from it.
- The model utilizes a reference model to prevent drastic changes; this reference model can be the initial base model or a solid checkpoint during reinforcement learning.
- Unlike Proximal Policy Optimization (PPO), GRPO does not require a value model to compute rewards. Value models are typically the same size as the policy model (the LLM in this case) and are updated during training. By dispensing with a value model, GRPO significantly reduces the computational cost of reinforcement learning.
The Training Process
With RL in mind, we now explain the training process used for DeepSeek-R1-Zero, the predecessor to DeepSeek-R1. The base model is DeepSeek-v3-base, a large language model built with a Mixture of Experts (MoE) architecture. In MoE models, the network consists of multiple expert subnetworks, but only a few are activated for each input. A gating mechanism dynamically selects the most relevant experts, making the model more efficient by reducing computational costs while maintaining high performance. In the figure below, we present a schematic of the training process.

The rewards are rule-based, and are either correct or incorrect. For mathematical problems, correctness can be verified using software, while for coding tasks, answers can be compiled or executed to determine validity.
Remarkable Highlights And Drawbacks
The remarkable features authors observed during and after the training of the zero version are the following:
- Increasing of the chain of thought: The chain of thought or reasoning trajectory is what is generated between inside the block
<think>...<\think>. This space is used by the model to generate human-like first person reasoning. The model was not awarded to increase the number of think tokens during the training, but along with the increasing accuracy, the model prefers longer chain of thoughts. This is an emergent property of the reinforcement learning. - The famous “aha” moment: This fascinating phenomenon emerged in an intermediate version of DeepSeek-R1-Zero within the reasoning trajectory. While solving a mathematical problem, the model generated the phrase “Wait, wait. Wait. That’s an aha moment I can flag here.” during the thinking stage. Following this realization, it chose a more promising path to solve the problem. As the authors noted, the model learned to rethink using an anthropomorphic tone, mimicking human-like reflection and self-verification.
- Strong reasoning capabilities: Benchmarks show that the model performance is really good on mathematical and logical problems, for example has a score of 95.9 in MATH-500.
However, some drawbacks were also noted:
- Language Mixing: The model exhibits poor readability and language mixing during the thinking process. Notably, correcting this in DeepSeek-R1 showed to a small degradation in the model’s performance.
From DeepSeek-R1-Zero to DeepSeek-R1
To fix the shortcomings of DeepSeek-R1-Zero, the authors implemented a number of extra steps to increase the model readability, helpfulness and harmlessness. Below you will find schematically the training process, starting on the top left.

Briefly, the training process goes as follows: 1. To prevent a cold start phase, the base model is fine-tuned with high quality chain of thoughts, including ones generated by DeepSeek-R1-Zero and curated by humans. This stage produces the Checkpoint 1 in the figure. 2. Then, the model undergoes the same large-scale reasoning-oriented reinforcement learning process used for DeepSeek-R1-Zero. In addition, it includes language consistency reward too. This stage produces Checkpoint 2. 3. The model is fine-tuned with reasoning data produced by Checkpoint 2, filtered and curated to keep only readable, coherent and single-language prompts. Non-reasoning data is also incorporated from the dataset used to train DeepSeek-v3-base, also chains generated by the model. This stage produces Checkpoint 3. 4. In this stage the authors are less specific on exactly what they did, but the aim of this stage is to run a secondary reinforcement learning stage to improve helpfulness, harmlessness and refine the reasoning capabilities. Aside from improving the reasoning capabilities with rule-based awards, the authors incorporate reward models to capture human preferences. Among other details, this stage produced DeepSeek-R1.
Model Distillation: Equipping The Power of Thinking to Small Models
As mentioned above, DeepSeek also released small distilled models, which are quantized and available on Ollama. These models’ sizes range from 1.5 billion parameters to 70 billion. The models were distilled using Qwen 2.5 (1.5b, 7b, 14b, 32b) and Llama 3.3 (8b and 70b) models, in parenthesis are the models’ sizes. DeepSeek-R1:7b is labelled as deepseek-r1:latest at it is the default model in Ollama.
Roughly, deepseek-r1:70b requires 42GB of VRAM, while deepseek-r1:30b needs around 22GB. Interestingly, deepseek-r1:14b requires just 11GB, and deepseek-r1:8b only 6.5GB—making the latter capable of running on a budget computer without a dedicated GPU.
The distillation process is depicted below.

Unlike the main model, distillation does not use reinforcement learning. Instead, it involves fine-tuning smaller base models on 800K curated samples from DeepSeek-R1. The authors demonstrate that this approach outperforms reinforcement learning for small models, with the distilled Qwen 2 version surpassing an equivalent model trained via RL. This result is quite relevant since distillation is much more cheaper than large-scale RL. Nonetheless, the authors comment that a RL stage on distilled models could boost their reasoning capabilities.
Performance of Distilled Reasoning Models on NLP Tasks
DeepSeek was primarily trained on reasoning tasks such as logic, mathematics, and coding. At first glance, natural language processing (NLP) tasks might not seem to directly benefit from deep reasoning capabilities. However, tasks like Named Entity Recognition (NER) and Part of Speech (POS) tagging can greatly benefit from the additional steps and introspection that reasoning models offer. Specifically, NER tagging requires a deep understanding of context, and often, a single pass may not suffice to capture the nuances of meaning. By generating thinking trajectories, reasoning models are able to better account for broader context, previous tokens, and potential ambiguities in entity identification, improving the model’s overall accuracy.
The potential we see here is that NER and POS tagging are rule-based tasks, where outputs are either correct or incorrect. As such, a large language model (LLM) could undergo the same reinforcement learning (RL) procedure used to train DeepSeek-R1. However, such an endeavor is beyond the scope of this post. Instead, we focus on exploring the raw capabilities of the distilled models on several NLP tasks, all while running locally using Ollama. See this post to learn more about Ollama and other tools to run LLMs locally.
A Previous Exploration with Llama 3.1
Before evaluating DeepSeek-R1, we conducted a similar analysis using Llama 3.1 70B across different quantizations and NLP tasks and compared the results with OpenAI’s models, it published in a previous blog post. Since DeepSeek-R1:70B and 8B are based on Llama 3.3, along this work we continuously compare the new results to those obtained with Llama 3.1 70B to assess the impact of reasoning trajectories on performance. We encourage you to take a look at that post to gain insights into how quantization and temperature affect LLM performance.
Named Entity Recognition (NER) Tagging
Named Entity Recognition (NER) Tagging is the task of identifying and classifying entities—such as names, locations, dates, and organizations—within a text. While it may seem straightforward, challenges arise when context is needed to disambiguate entities. For example, in the sentence “Apple is set to release a new product in Paris,” “Apple” could refer to the company or the fruit, and “Paris” could mean the city in France or a person’s name. Correct classification requires understanding the broader context. Now, let’s take a look at how the distilled DeepSeek-R1 models perform on NER tagging.
Model Distilled From Llama 3.3 70B
Below we plot the F1 scores per tag and the confusion matrix using deepseek-r1:70b (a model distilled form Llama 3.3). Compared with Llama 3.1 70B (previous post) it performs generally slightly better, especially with MISC entities.


How Long Are the Reasoning Trajectories Compared to Accuracy?
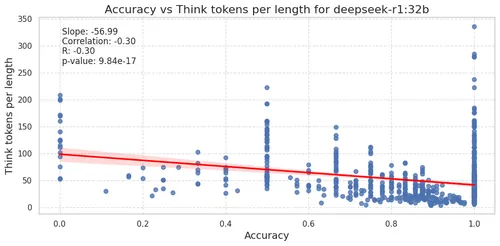
DeepSeek-R1’s team observed that the model learned to increase the reasoning trajectory (on average) to handle the complexities of a given problem, ultimately improving accuracy. This self-adjustment is part of the model’s evolution and represents an emergent property. To further investigate this phenomenon, we explored how accuracy correlates with the ratio of reasoning trajectory length to input size in NLP problems. Normalizing by input size seems reasonable, as longer sentences naturally require longer thinking patterns as we observed that the models tend to cut apart sentences and analyze each word.

Interestingly, we found a small but statistically significant anticorrelation between accuracy and reasoning tokens per input length. That is, the model performs better when reasoning trajectories are relatively shorter. This is, either the model is overthinking and/or it emerges due to a hidden pattern in the questions. We think that it is possible that this behavior would be reversed for a model specifically trained for NLP tasks.
Model Distilled From Qwen 2.5 32B
Such anticorrelation is observed also using the distillate based in Qwen 2.5, see figure below.
Comparing All Models
We computed the correlation discussed above for all distilled models. In the figure below you will find the correlations and slopes with confidence intervals and p-values.

Notice that the observed anticorrelation is present in other models too, but it is more notable in the largest models.
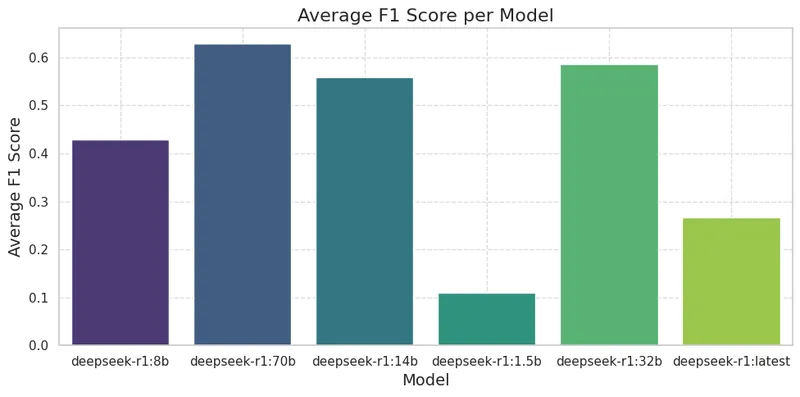
Below, we show the average F1 scores for all models. Notably, DeepSeek-R1:14b, one of the relatively smaller models, performs almost on par with the larger ones.
Key Observations For NER Tagging
- The best performing model is DeepSeek-R1:70b, giving an average F1 score slightly above 0.6, essentially on par with the best quantizations of Llama 3.1 70B (previous post).
- The models used were not specifically trained to excel in NLP tasks, but we believe that the reinforcement learning technique could lead to improved models, as certain NLP tasks may benefit from reasoning trajectories.
- Contrary to our expectations, the accuracy is correlated with shorter reasoning trajectories. As mentioned above, this could be indicative of the model not being trained under RL for NLP tasks.
Part Of Speech (POS) Tagging
Part-of-Speech (POS) Tagging is the task of assigning grammatical categories (such as noun, verb, or adjective) to each word in a sentence. While simple cases are straightforward, ambiguity makes POS tagging challenging. For example, in the sentence “I saw the bat fly,” the word “bat” could be a noun (the animal) or a verb (to strike), and “fly” could be a noun (the insect) or a verb (to move through the air). Understanding the correct meaning requires contextual reasoning, making POS tagging a non-trivial NLP task. Now, similarly to the previous section, let’s take a look at how the distilled DeepSeek-R1 models perform on POS tagging.
Model Distilled From Llama 3.3 70B
The analysis and results are very similar to the ones of NER tagging. Below we plot the reasoning tokens per input length vs. accuracy and found again an anticorrelation.
Comparing All Models
Similar to NER, we computed the correlation discussed above for all distilled models. In the figure below you will find the correlations and slopes with confidence intervals and p-values.
The results are quite similar to those of NER, though with larger confidence intervals. Nonetheless, the anticorrelations persist and remain statistically significant.
Below, we show the average F1 scores for all models. And again, DeepSeek-R1:14b, one of the relatively smaller models, performs almost on par with the larger ones.
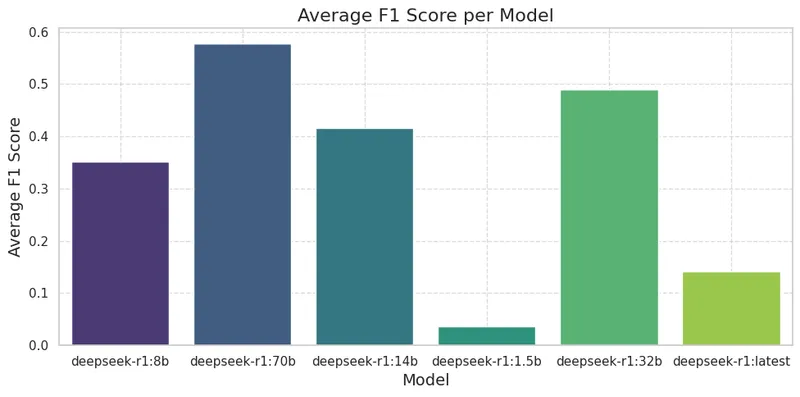
Key Observations For NER Tagging
- The observations are basically the same to those of NER.
- This time the results perform also on par of the best quantizations of Llama 3.1 70B (previous post).
Sentiment Analysis
Sentiment analysis is a fundamental NLP task that involves determining the emotional tone of a given text. It is widely used in applications such as customer feedback analysis, social media monitoring, and market research. Unlike traditional text classification, sentiment analysis must capture nuanced expressions, sarcasm, and contextual dependencies, making it a more sophisticated challenge for language models.
Find below the results for bi-class sentiment analysis (only positive and negative sentiments).
The performance of DeepSeek-R1:32b (the model based on Qwen 2.5) is slightly better than that of DeepSeek-R1:70b (the model based on Llama 3.3). Interestingly, all models perform relatively close to each other, with only the smallest model, DeepSeek-R1:1.5b, lagging behind. In fact, DeepSeek-R1:1.5b failed more than 80% of times to give any sentiment at all and/or follow the instruction correctly.
Multi-class
Multi-class sentiment analysis, which includes neutral sentiment alongside positive and negative, presents a significant challenge for large language models (LLMs). Unlike binary classification, where the model only needs to distinguish between two polarities, a neutral class introduces ambiguity, requiring the model to recognize subtle or mixed sentiments. Many statements are context-dependent and may not express a strong opinion, making it difficult to draw clear boundaries between neutral and slightly positive or negative sentiments. Additionally, training data for neutral sentiment is often less consistent, as human annotators may disagree on what qualifies as truly neutral, further complicating the model’s ability to generalize across diverse linguistic expressions.
Find below the F1 scores for multi-class sentiment analysis.
As expected, the models struggle significantly more with sentiment classification in the multi-class setting. To better understand this behavior, let’s examine the confusion matrix.
The lower F1 score of neutral sentiment is due mainly to it being confused with positive or negative, also there is a small contribution from negative sentiments being predicted as neutral. Let’s now check out how the long are the reasoning trajectories. Below we show the figures of the matches of negative and neutral sentiment respect to think tokens per input length. This time, the axes are flipped compared to previous plots for better visualization—rather than accuracy, we plot matches.

Although the correlation is not statistically significant, there is a clear tendency for accuracy to increase with the length of the reasoning trajectory, with a slightly stronger effect for negative sentiment classification. The results for positive sentiment are similar to those for negative sentiment.
Comparing All Models
Similar to the previous tasks, below we present the correlation and slope between accuracy and reasoning tokens per input length. Our reasoning follows a similar argument: longer sentences may inherently require more complex reasoning trajectories. By analyzing this correlation, we aim to better understand how reasoning depth impacts sentiment classification accuracy.

Some models exhibit tendency to anticorrelation, although not statistically significative, especially DeepSeek-r1:14b and 8b. To finish the model comparison, find below the average F1 scores multi-class sentiment analysis. The best performing model is DeepSeek-R1:70b.

Key Observations for Sentiment Analysis
- As expected, all models struggle more when classifying neutral sentiments.
- All models perform slightly better on positive sentiments than on negative sentiments.
- Unlike NER and POS tagging, multi-class sentiment analysis performance improved compared to Llama 3.1 70B (previous post), with an average F1 score above 0.6—on par with GPT-4o.
- Although DeepSeek-R1:1.5b achieved a reasonably good F1 score, it failed to accomplish the task most of the time (above the 60%), highlighting its inconsistency.
- The best performing model (DeepSeek-R1:70b) tends to generate longer reasoning trajectories when it decides that the sentiment is neutral. This is a signature of the struggle that neutral sentiment introduces.
NLP Using O1 and O3-mini
In order to have a reference of how well open-source small reasoning models compare to OpenAI’s reasoning models available online, we study NER tagging and multi-class sentiment analysis using o1 and o3-mini models. We compare the results also to the ones obtained with gpt-4o, gpt-4o-mini, gpt-4-turbo and gpt-3.5-turbo from our previous post.
NER
Find below the F1 scores per entity using o1 and o3-mini.
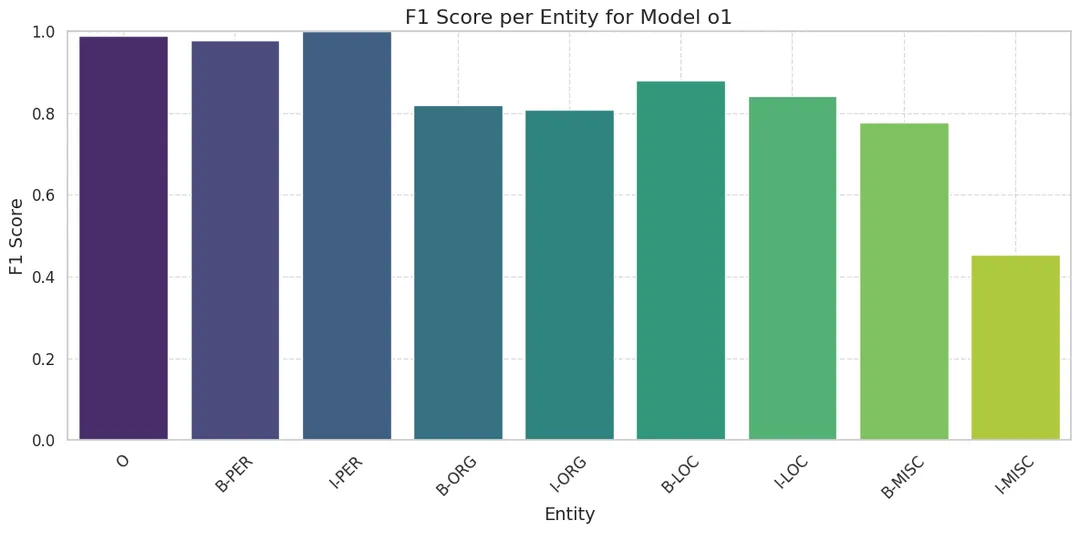
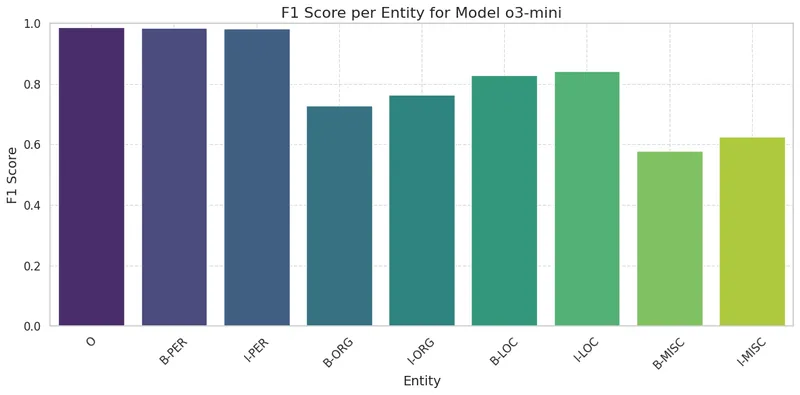
Both models perform much better than DeepSeek models, with all tag F1 scores showing significant improvement, especially for MISC entities. In fact, o3-mini performs similarly to GPT-4o (previous post). Moreover, the confusion matrix for o1 is almost diagonal, as shown in the figure below.

Below we plot the reasoning tokens per input length vs. accuracy and found again an anticorrelation.

The conclusions we can draw here are limited, as we cannot directly access the reasoning trajectories generated by OpenAI’s models. However, the API does report the length of these trajectories. This raises an open question: either the model is overthinking, or there is an underlying complexity in the task that we have yet to fully understand.
Key Observations For NER Tagging
- OpenAI’s models perform significantly better on NER than distilled DeepSeek-R1.
- However, it’s important to note that the DeepSeek models used are both distilled and quantized using Q4_K_M quantization.
- We believe open-source models have the potential to reach performance levels similar to o1’s by leveraging the structured nature of NER and POS tagging. Since these tasks are largely rule-based, reinforcement learning (RL) focused on NLP could further enhance performance.
- Less aggressive quantization methods could also be explored when available to preserve accuracy.
Multi-class Sentiment Analysis
Find below the F1 scores for multi-class sentiment analysis using o1 and o3-mini models.
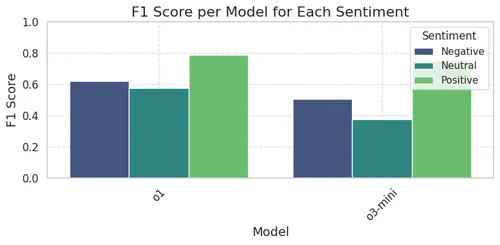
DeepSeek-R1.70b (the best performing distilled DeepSeek-R1 model) performs slightly better than o1, the performance on positive and negative sentiments is similar, but DeepSeek-R1 performs better on negative sentiments. Below we plot the confusion matrix for o1. As usual, it struggles predicting negative sentiments.

Below we show the figures of the matches of negative and neutral sentiment respect to think tokens per input length. This time, the axes are also flipped compared to previous NER plots for better visualization—rather than accuracy, we plot matches.
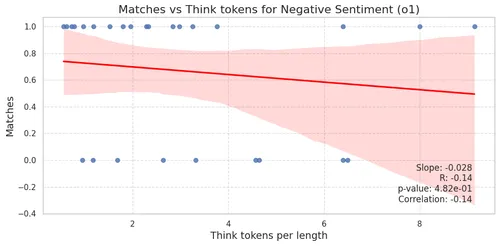
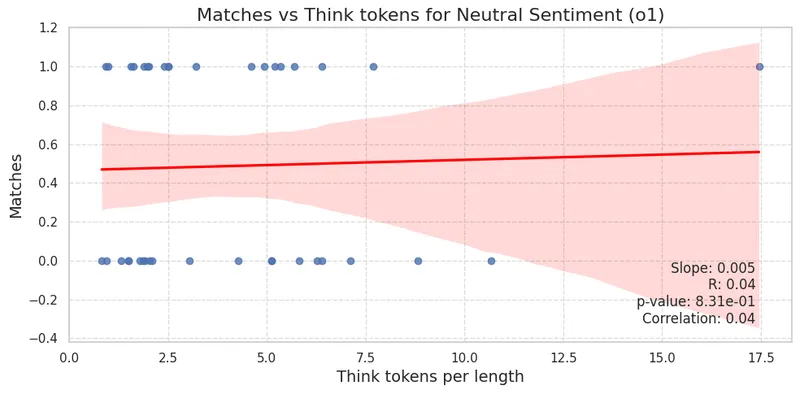
Similar to DeepSeek-R1, although not statistically significant, there is a slight tendency for the model to produce relatively longer reasoning trajectories when classifying neutral sentiment. To finish the analysis, we compute the average F1 scores to compare with the results from our previous post.
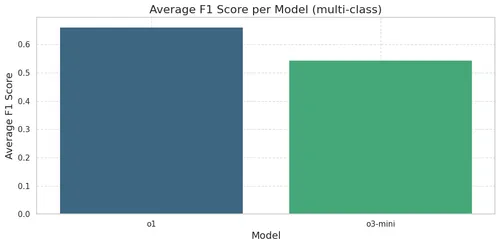
Model o1 performs similarly to GPT-4o-mini (the best-performing non-reasoning OpenAI model from our previous analysis), with average F1 scores around 0.65. Therefore, there are essentially no improvements in this task compared to previous OpenAI models.
Key Observations for Sentiment Analysis
- As expected, both models struggle more when classifying neutral sentiments.
- Both o1 and o3-mini models perform slightly better on positive sentiments than on negative sentiments.
- DeepSeek-R1:70b performs slightly better than o1.
Closing Insights
A Comment on the Aha Moment
The “aha moment” is definitely a big breakthrough and a beautiful phenomenon, signaling that new behaviors can emerge in LLMs when subjected to reinforcement learning. In addition to this, we believe that the very concept of reasoning trajectories will gain momentum as an active and fruitful research field, especially now that an open-source resource is available.
As a technical note, the generation of anthropic-like reasoning blocks simply means that the model can reproduce reasoning patterns that lead to the correct answer. However, the underlying architectures remain fundamentally unchanged—LLMs still generate reasoning tokens in the same traditional way as any other tokens. This distinction is important because the real breakthrough lies in the reinforcement learning technique that enabled LLMs to develop structured reasoning capabilities.
Moreover, to grasp what makes these models special, one must recognize that LLMs already exhibit a form of intelligence. The key innovation is that reinforcement learning encourages them to generate additional tokens producing a reasoning trajectory, reinforcing structured decision-making rather than relying solely on statistical pattern matching. This shift towards reasoning trajectories represents a compelling direction for future research.
Some Examples of Aha and Reflection Moments we Spotted.
Find below some examples using DeepSeek-R1:70B, we focused on the aha moment, not in the final answer.
- Question: Suppose an investor is offered two investment options:
- A one-time payment of $100,000 today.
- A guaranteed annuity of $12,000 per year for the next 10 years.
- Question: A scientist observes that the mass of a radioactive substance decreases over time following the equation: $$ m(t) = m_0 e^{-kt} $$, where m0 is the initial mass, k is a positive decay constant, and t is time in hours.
- A sample starts with m0 = 200 grams. After 5 hours, the mass is measured as 50 grams. Find the decay constant k.
- Determine the half-life of the substance (i.e., the time when $$ m(t) = m_0/2 $$).
- A sample starts with m0 = 200 grams. After 5 hours, the mass is measured as 50 grams. Find the decay constant k.
Replication of DeepSeek Training: Impact of Cheaper and Reliable Models on Business Models
DeepSeek’s breakthroughs have essentially made high-quality, cost-effective reasoning models accessible to the masses. It is only a matter of time before other major companies replicate and distill their own reasoning models, particularly given Meta’s commitment to open-source AI development.
Beyond the influence of large tech players, this shift has profound implications for smaller AI companies. With open-source reasoning models, these companies now have the opportunity to develop more sophisticated, customizable AI solutions without relying on proprietary models from industry giants. This not only reduces costs but also enhances privacy, as businesses can fine-tune models locally to align with their specific needs and data policies. As a result, we expect a surge in innovative applications where reasoning capabilities are embedded into specialized domains, further democratizing AI advancements.
At Austin Ai, we can leverage these open-source advancements to deliver custom AI solutions for businesses. Our expertise in implementing and fine-tuning reasoning models empowers companies to build secure, privacy-conscious, and efficient applications, tailored to meet their unique needs and accelerate their AI-driven growth.